 André König
André König- Nov 08, 2023
- 10 Min Read
- SQLite
Hybrid SQLite
Enhance your web application's read performance without compromising scalability.
Wouldn't it be amazing if retrieving data from a database were instantaneous? So much so that it felt as though the actual data was directly embedded into the user interface? You might wonder, why the focus is on reading data.
Web-based systems are predominantly read-intensive powerhouses. The majority of user interactions revolve around data consumption rather than mutation. To achieve optimal performance, it's ideal to have this data as close to your service as possible. Yet, we often find ourselves crossing network boundaries to fetch data from the database cluster.
This article examines SQLite on the Edge, a truly serverless database that brings your data as close to your application as possible. However, like any technology, SQLite comes with its own set of trade-offs. We will explore why SQLite is an appealing choice for web-based applications and, more importantly, how we can work around its limitations.
Understanding SQLite
The "Lite" in the name suggests that it is a scaled-down or simplified version of something more "mature" and "enterprise-grade," like Postgres, Microsoft SQL Server, or even Oracle Database. While these are all excellent systems, they won't help you bring the data closer to your application, as they still run on remote machines.
Fortunately, there are database systems that don't require a dedicated machine. SQLite, for example, seamlessly integrates with your application, eliminating the need for a separate server process. It's like having a dedicated personal assistant, always available to retrieve data at a moment's notice. With extensive SQL standards support and a rich feature set, including transactions, triggers and subqueries, SQLite offers impressive capabilities in a compact library. Naturally, every system has its unique characteristics, so here's a brief overview of SQLite's advantages and disadvantages:
Pros
- Serverless: The whole database is persisted in a single file which is easy to replicate (e.g. "download" the production database and use it to hunt a bug in your local development environment).
- Embedded: As an integral component of the application, SQLite removes the necessity for data to traverse a network, thereby improving read performance.
- Full SQL Support: Despite its simplicity, SQLite does not compromise on features, providing comprehensive support for SQL standards.
Cons
- Single Writer Limitation: SQLite allows only one write operation at a time. This can be a bottleneck when your application is write-intensive.
- Limited Concurrency: Owing to its single-threaded nature, SQLite may not be the ideal choice for applications that require high levels of concurrent access.
It doesn't scale!
While the positive aspects are quite compelling, the negatives are real deal-breakers, as they prevent your application from scaling horizontally. First, you have to ensure that multiple instances of your application can access the database file. In other words, you have to establish a network filesystem, which renders the argument of having the database close to your application obsolete. Secondly, only one process can access the database at the same time. Even if multiple processes can reach the database file, only the first instance of your application gains exclusive write access, leaving the others out in the cold.
SQLite in the Cloud?!
Often, a technology arises that seems like the perfect fit, but one negative aspect prevents us from using it. What do engineers do in such a situation? That's right, they develop additional software to eliminate the trade-offs. This has occurred in recent years.
Although it may seem counterintuitive, the solution to addressing the scaling issue involves moving the database to the cloud, but with a twist. Instead of adopting a full client/server model, the answer lies in implementing a hybrid model. This approach allows us to overcome the single-writer problem by maintaining a read-only replica of the database locally while relocating the write database to the cloud.

Upon launching an instance of your application, a local replica of the remote database is embedded. After populating the local replica, the application retrieves data from it. Because the replica is stored on the local filesystem, which the application can access, read speeds are significantly faster.
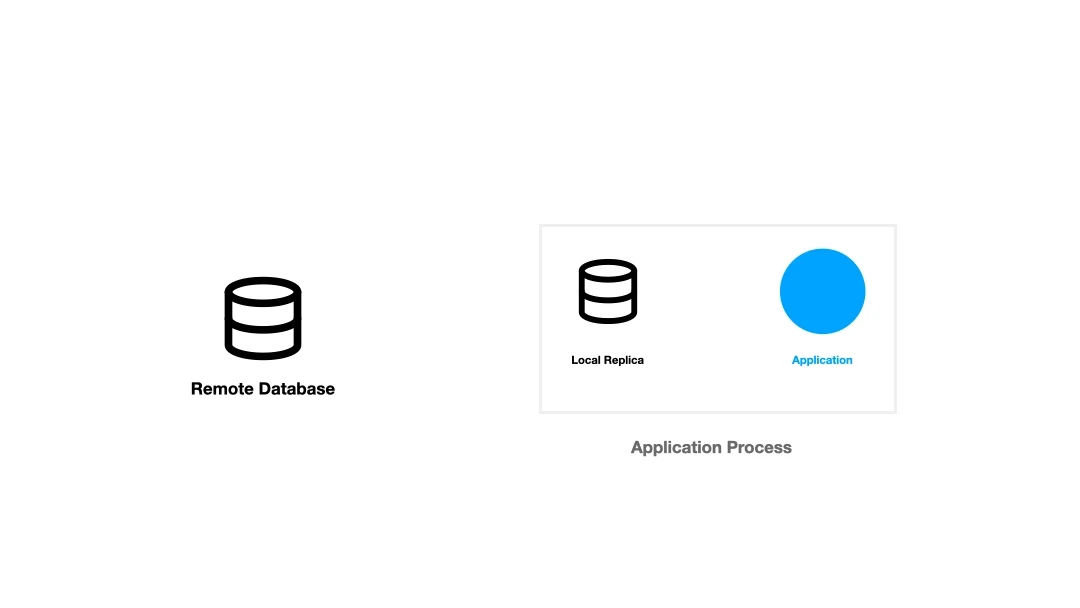
Now, here's the twist. When it comes to writing data, it doesn't occur on the local replica. Instead, the write operation is directed towards the remote database. Once the write operation is successful, the local replica synchronizes, ensuring that the application continues to benefit from the performance improvements of having a local database.
Since the original SQLite library did not support this type of architecture, the skilled team at turso.tech created a fork of SQLite and incorporated this method into libSQL.
libSQL ships with the following features:
- Possibility to embed replicas.
- A server for hosting the remote "write" database.
- SDKs for all major programming languages: Rust SDK, JavaScript SDK, Python SDK and Go SDK.
You can host the server on your own or use the service provided by the Turso team. Besides offering the described architecture, the Turso service also provides read replicas on the edge which is pretty awesome as well. This is useful if your application itself is deployed on the edge. After writing to the remote database, Turso will distribute the new state to all their edge destinations, so that your application can sync with the closest replica destination. This minimizes the sync time tremendously.
Benchmarks
As we outline this approach, it's crucial to battle-test this architecture with solid data. The benchmark scenario is divided into two tests: the first one involves executing queries against a Postgres database (deployed on Supabase), while the second one involves executing the same queries against a libSQL-based database deployed on Turso and running in hybrid mode (with an embedded replica and remote write destination).
You can find the sources for measuring the performance metrics in this repository. It is important to note that both probes operate under the same conditions, specifically:
- Same table structure.
- Same execution steps (Postgres / libSQL).
- Same region for the remote database (Frankfurt, Germany).
- Performed 250
SELECTqueries against the database. - Executed the benchmark in the Cloud on a VPS (4 vCPU, 16 GB RAM) located in Nuremberg, Germany.
Results
Evaluation
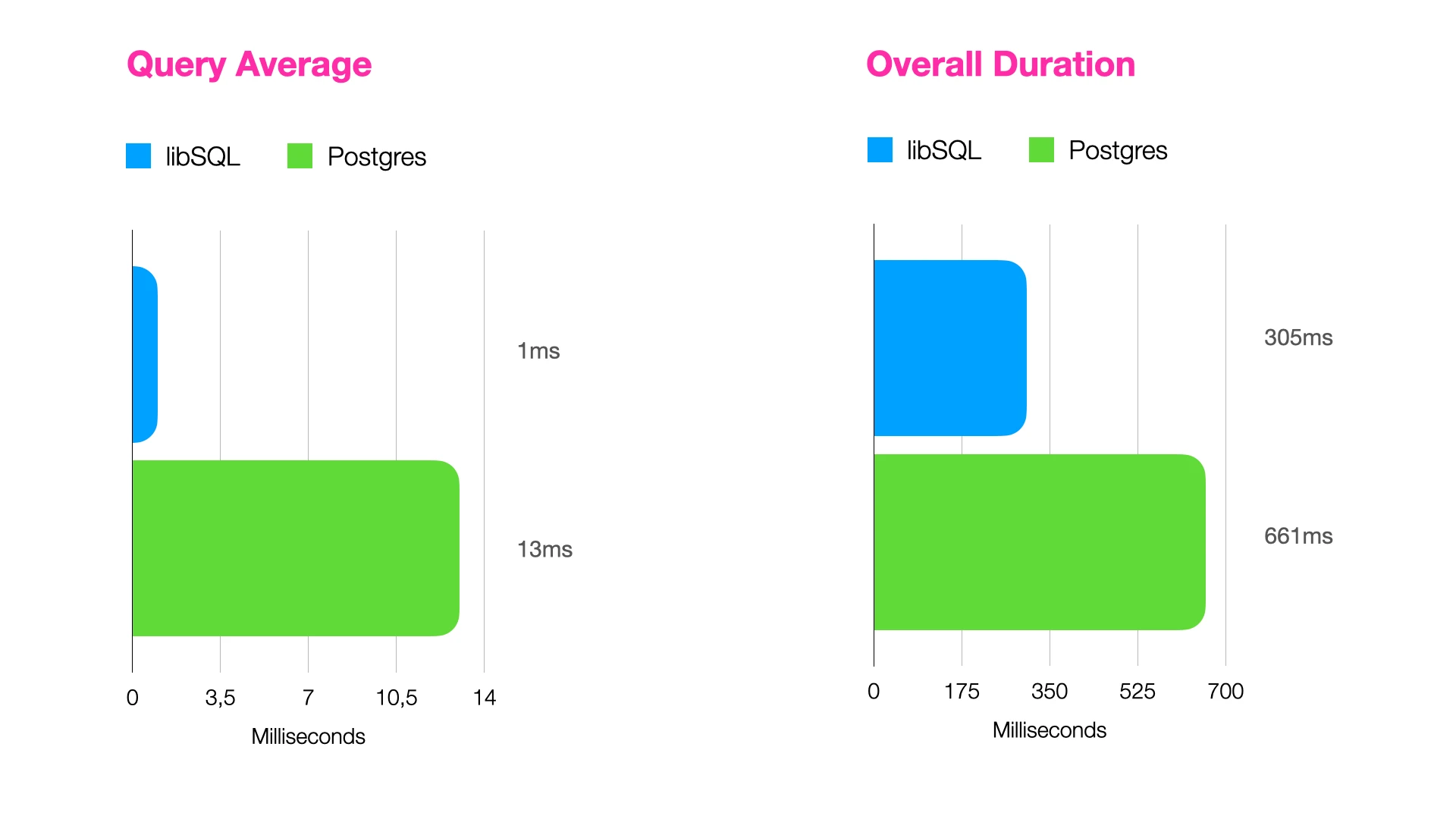
🏎️ libSQL demonstrated a 13x performance improvement per query compared to Postgres.
In summary, when comparing the execution times of identical queries on two different database systems, SQLite and Postgres, it becomes evident that SQLite outperforms Postgres significantly. Specifically, running the same query on the SQLite database, which is facilitated by the libSQL library, results in a remarkable 13-fold increase in speed compared to executing the same query on the Postgres database.
During the benchmarking process, a total of 250 SELECT queries were executed on each of the two databases. The Postgres database system completed the entire benchmark in 661 milliseconds, averaging 13 milliseconds per query. In contrast, the libSQL library finished the whole benchmark in a mere 305 milliseconds, with an impressive average of only 1 millisecond per query.
This substantial difference in performance highlights the efficiency and speed of libSQL when compared to Postgres, making it a more attractive option for use cases where read performance is important.
Potential Challenges
Although the benchmark results are truly astonishing, we must also discuss the potential challenges of the hybrid model in terms of data consistency. By default, it is safe to say that a mechanism where a delta of changes needs to be downloaded is, in fact, an eventually consistent system. That said, the question is how to minimize the window in which data might be out of sync.
When running only a single instance of the application, synchronizing changes from the remote database to the local replica is not a significant issue, as you can sync the changes immediately following your write operation, such as:
import { client } from "./infrastructure/database.ts";
type ProfileDto = Readonly<{ id: string; firstName: string; lastName: string;}>;
async function insertProfile(dto: ProfileDto) { await client.execute({ sql: `INSERT INTO profile (?, ?) WHERE id = ?;`, args: [ dto.firstName, dto.lastName, dto.id ] });
// Refresh the local replica right after writing data await client.sync();}When your application scales horizontally and has multiple instances, each with its own replica, managing synchronization becomes a completely different challenge. It is crucial to ensure that all instances keep their replicas in sync. Fortunately, the Turso team asserts that calling sync() is a relatively inexpensive operation when no changes needs to be synced. As one solution, you could ask for changes via sync in a very short duration (< 1 second).
In the test setup mentioned, we inserted 1,000 rows. Replicating these rows into the local database took 3,758 ms.
Conclusion
You should aim to optimize the read performance when building web-based applications. This is a serious challenge when your data layer only operates in a client/server model. Having the data local, but still scaling your application horizontally when the need arises, was simply not possible in the past.
Fortunately, with the work of the Turso team on libSQL operating a hybrid approach became feasible. Having a local copy of your database that is directly embedded within your application makes data read operations blazingly fast without sacrificing data consistency when it comes to writing operations.
These developments promoted SQLite in general to be a serious consideration when building scalable and fast web-based systems.
I see a bright future for this tech. Not just when building MVPs, but especially when building enterprise software as well.